Data De-Identification - An Easier Way to HIPAA-Compliance
Creating a HIPAA-compliant product doesn’t have to be a harrowing experience, but most teams unwittingly choose the slowest, riskiest, and most challenging path to compliance. This post seeks to shed some light on a faster and simpler approach: Data De-Identification.
If you take the hard path, retrofitting an existing application to become HIPAA-compliant can be a huge undertaking:
- You’ll need to start with a massive effort to refactor your codebase to satisfy all of the mandated Technical Safeguards.
- Next, all of the third party libraries, frameworks, and services that helped jump-start your initial application development will come under the microscope. You’ll need to audit them to ensure compliant behavior or jettison them entirely and reimplement them in-house.
- Then comes infrastructure. You’ll likely have to migrate to an entirely new hosting provider. Even if you’re already on a HIPAA-ready provider, you’re not necessarily safe: you’ll still have to pare down your usage until you fit neatly in the small subset of services that are covered under their business associate agreement, meaning more work for your development team.
And the story isn’t much better for greenfield projects – you can avoid the massive refactor, but you will still face the rest of the challenges. Your colleagues working outside of healthcare will race to market in a fraction of the time, because they can take advantage of countless SaaS products and open-source frameworks that save time but aren’t HIPAA-compliant. Meanwhile, your team will spend months struggling to build from-scratch components that they’ve taken for granted until now.
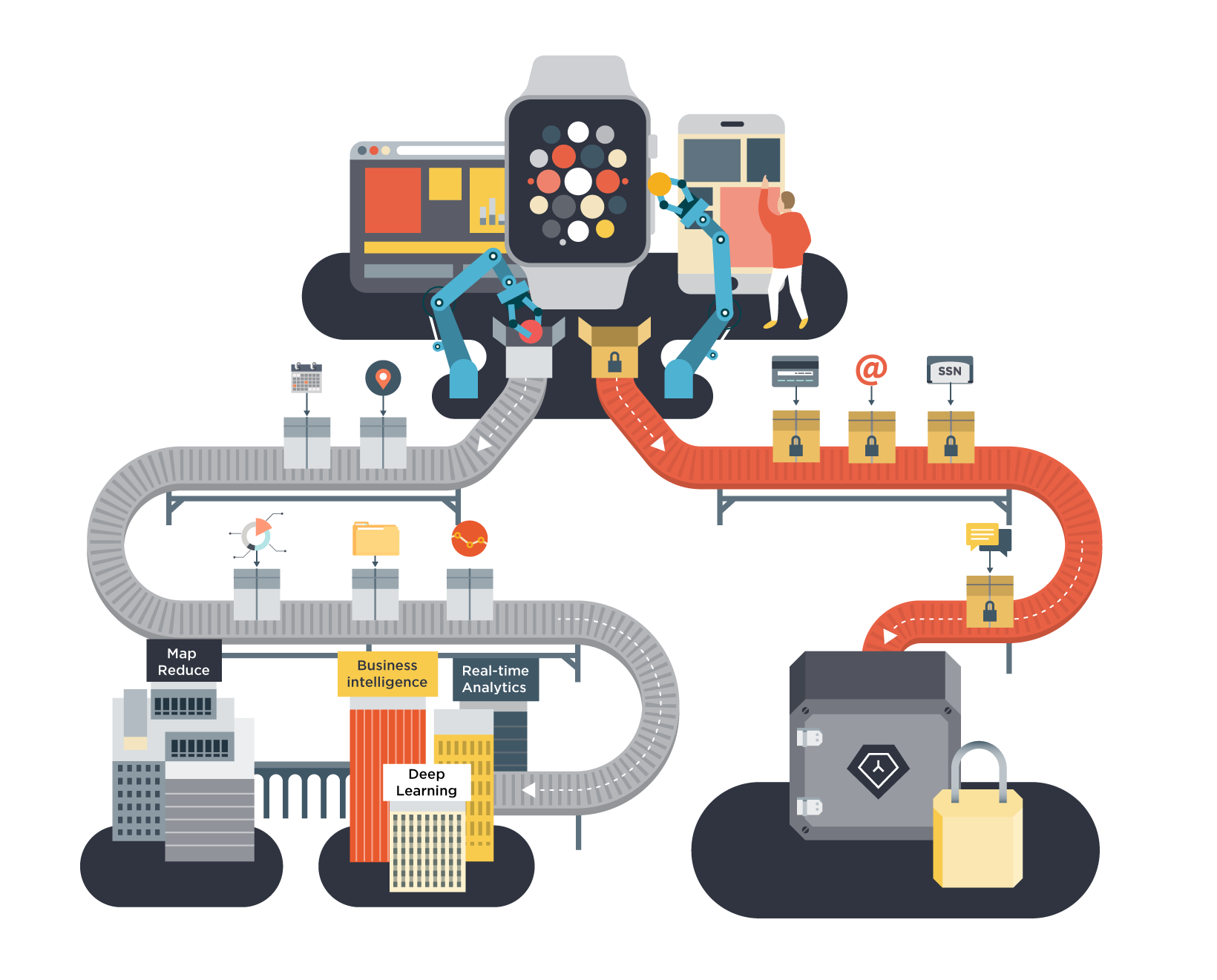
Splitting your data
Fortunately there’s a better way: Data De-Identification. It involves separating out Protected Health Information (names, email addresses, physical addresses, health information, and other identifying information) and storing that data (and only that data) in a separate HIPAA-compliant data store. This frees you to host your application, and store the rest of the de-identified data, in an environment not subject to HIPAA.
If this sounds familiar, it’s probably because it’s a lot like using Stripe to store card payment information. In that case, rather than storing the 16-digit credit card number in your database and incurring the burden of PCI Compliance, you partition your application’s data into regulated credit card data (stored in Stripe) and non-regulated application data (stored in your database). In exactly the same way, Data De-Identification allows you to remove the majority of your data from the scope of HIPAA.
The result is that you can run the de-identified stack on any platform, write it in any language, and use any framework or SaaS tool you want without worrying about compliance issues. You will have to make changes to your application, but doing so will be much closer to the effort required to integrate Stripe than to the massive rebuild described above.
In the rest of this post, we will walk you through what you need to know and consider before proceeding, both technically and legally.
How it works in practice
Let’s imagine that you have an existing messaging application you’d like to market to medical practices for secure patient communication. You know your application doesn’t currently meet HIPAA regulations, and the prospect of reaching compliance is daunting: you use third party SaaS products to send cross-platform notifications, you host your servers in a non-compliant shared environment, and you have a considerable amount of application logic that you don’t want to rewrite.
If you find yourself in a situation like this, de-identification is definitely worth considering. In this model, you store all Protected Health Information (PHI) in an HIPAA-secure environment. Your application data (conversation members, unread message counts, message timestamps, visibility rules, etc.), which contains no personally identifiable information, will continue to be stored in your primary database. The de-identification process is automatically handled by the client application – it sends any identifiable data to a HIPAA-secure environment and the remaining, anonymous, application data to your servers. Your servers will only interact with de-identified data, which is not regulated by HIPAA.
In order to load the necessary data to show a conversation thread in your client application, the process might then look something like the following:
- First, the sender ID, recipient ID, and list of message IDs are loaded from your server. This data is not identifying, and it may contain application metadata like a read/unread flag, timestamps, source device type, etc.
- Then, the sender’s name, recipient's name, and message content are loaded from the secure PHI store. (Note: you’ll want to store any free-text, like message bodies, in the PHI store, since users could put anything in those fields, including identifying information.)
- Finally, the data is shown to the end-user. The fact that data is fetched from two different sources will be invisible to your users.
Because your primary stack is de-identified, you will have the flexibility to use any framework or tool to store, analyze and act on your data.
This structure will require modifications to your client applications and minor changes to your data model (as you will be storing references to data instead of the data itself). However, it is a lot less invasive than rewriting your entire application and moving it to a new hosting environment to meet HIPAA regulations.
The legal side of things
From a legal perspective, there are three things you’ll need to be sure of: that de-identification has been done correctly, that you have sufficient authorization to perform the de-identification, and that you are using the de-identified data within the parameters of HIPAA.
In terms of what counts as de-identified, two standards are accepted under HIPAA – the “safe harbor” method and the “expert determination” method:
- The safe harbor method involves stripping the PHI of certain identifiers. As long as you can show that the remaining information (alone or in combination with other information) cannot identify an individual, that information is de-identified.
- Alternatively, if the application data that you need to store on your servers requires you to keep any of those identifiers, you can call in an expert to perform a statistical analysis to determine whether that data set can be used to identify individuals. If the expert determines that risk to be “very small”, the data is considered de-identified.
While it may seem that the safe harbor method is more straightforward, you should keep in mind that the list of identifiers in the HIPAA rules is very broad and includes data elements that would otherwise not seem useful to identify a person, such as their professional title (for example, the job title “Senator” could go a long way to identifying an individual). For this reason, you’ll need to be careful when comparing the data sets and elements you plan on keeping on your servers with the HIPAA list to ensure that they do in fact count as de-identified.
In terms of authorization, you’ll need to check that your customer agreements allow you to perform the de-identification. If your customers are health care providers, they are likely to be covered by HIPAA themselves and will probably require you to enter into a business associate agreement (BAA). HIPAA requires these agreements to contain specific language about the uses and disclosures you will be allowed to engage in on the provider’s behalf, including the act of de-identifying PHI. If you work with a customer on an enterprise basis, you may need to adapt your BAA for each project for that customer.
Finally, it’s important to make sure that you are using the PHI and the de-identified data in accordance with HIPAA. The regulations generally limit your use of PHI to tasks necessary for the performance of services for HIPAA-covered entities (your customers). This has been interpreted to exclude any use of PHI for business purposes unrelated to your agreement with the customer.
De-identified data, on the other hand, is no longer PHI. As a result it is not regulated by HIPAA and can be used more freely: for example, for your own product research and development. However, the same isn’t true of aggregated data – that is, PHI from different HIPAA-compliant customers which is combined to perform data analysis for those customers. Your use of aggregated data will depend on your agreements with affected customers: if you plan on using any data provided by them or derived from their PHI, you should check that this is allowed both under your agreements and the HIPAA rules.
A better way forward
If your team is building a HIPAA-compliant application from the ground up or is making an existing application HIPAA-compliant, consider taking the Data De-Identification route. By storing personally identifiable information in a secure, HIPAA-compliant system like TrueVault, your team can move quickly and freely.
If you’re interested in more information about how TrueVault can help you with Data De-Identification, please get in touch.
JoAnna Nicholson is an attorney in Nixon Peabody’s Health Care practice group. Her practice centers on corporate, transactional and regulatory counsel within the health care industry, with a focus on state and federal privacy issues, including HIPAA and HITECH Act compliance, as well as data breach response strategies. JoAnna can be contacted by phone at 516-832-7611, or by email at jrnicholson@nixonpeabody.com.